Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
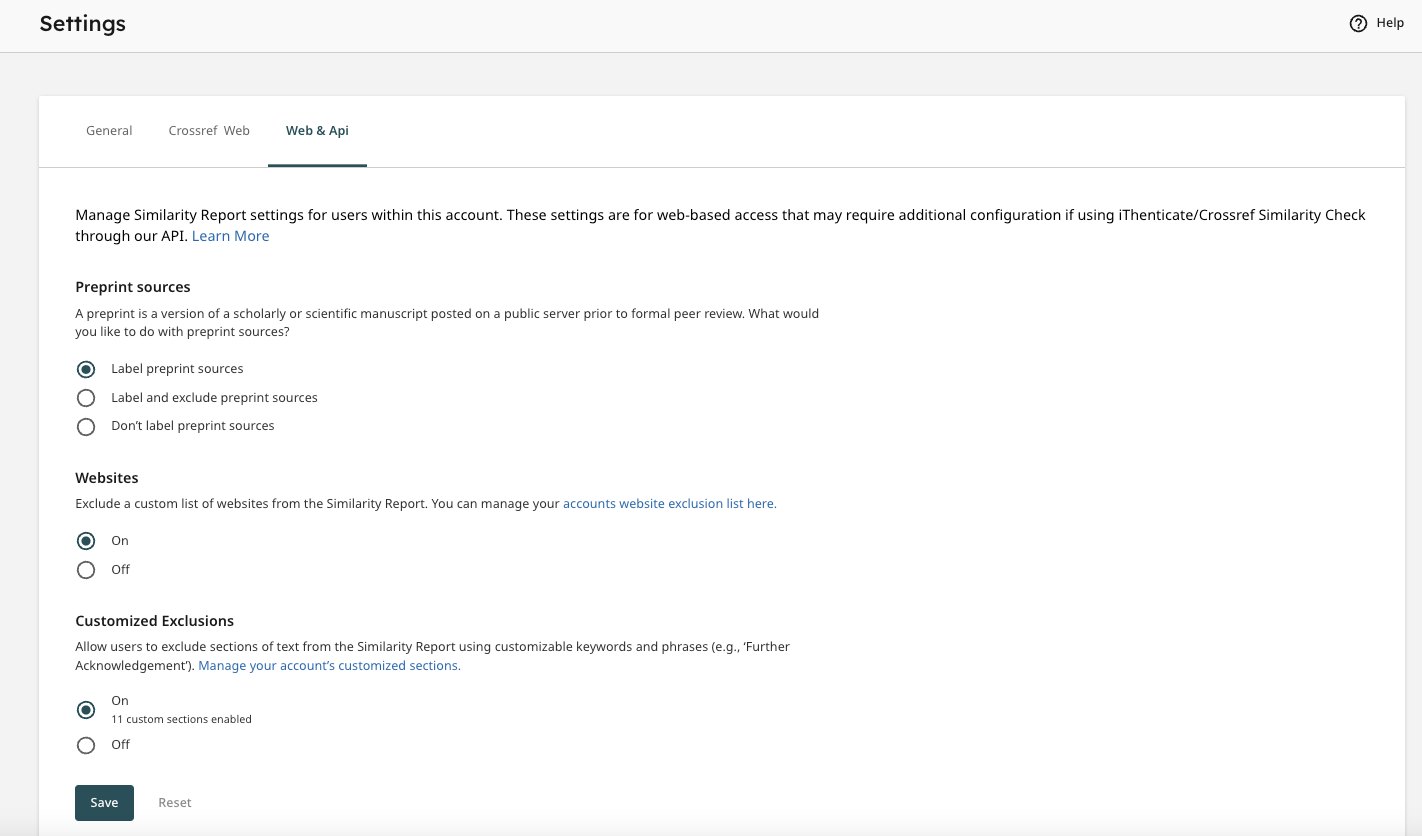
This section is for Similarity Check account administrators using iThenticate 2.0 through the browser, and describes how you can manage exclusions within your account settings..
Not sure if you’re using iThenticate v1 or iThenticate 2.0? More here.
Not sure whether you’re an account administrator? Find out here.
Exclusions
If you want to exclude items from your Similarity Report results, you can do this by clicking on Settings in the left hand menu in iThenticate 2.0 homepage. There are two tabs where you can change different items - one is labelled Crossref Web, and the other is labelled Web and API. Here are the various items you can exclude.
Preprint Label and Exclusions
iThenticate 2.0 introduces a new feature which will automatically identify preprint sources within your Similarity Report. This will allow you to easily identify preprints so your editors can make a quick decision as to whether to investigate this source further or exclude it from the report.
In order to start using this feature you will need to configure it within the iThenticate settings by logging directly into your iThenticate account. You can find instructions on how to configure this feature in Turnitin’s help documentation.
You also have the option to automatically exclude all preprint sources from reports. All excluded preprints will still be available within the Similarity Exclusions panel of your Similarity Report and can be reincluded in the report.
Further details of how preprints appear within the Similarity Report can be found in Turnitin’s help documentation .
The Website Exclusions setting will allow you to automatically exclude all matches to specific websites. Instructions on how to turn on and configure this feature can be found in Turnitin’s help documentation.
This feature will only exclude matches in the Internet repository. If a journal website is added to the list of excluded websites then all pages which have been crawled and indexed into Turnitin’s Internet repository will be excluded. However, journal articles from that journal which appear in the Crossref repository will not be excluded.
This feature will apply to all submissions made to the iThenticate account; including all web submissions and submissions made through any integration.
All excluded matches will still be available within the Similarity Exclusions panel of your Similarity Report and can be reincluded in the report. Further details of how these exclusions will appear can be found in Turnitin’s help documentation.
Customized Exclusions
A new feature in iThenticate 2.0 is Customized Exclusions. The Customized Exclusions setting allows administrators to create sections of text that can be excluded from the Similarity Report. Administrators can tailor these keywords and phrases to best meet the needs of their organisation (for example, ‘Further Acknowledgments’).