A couple of months ago, Ludo Waltman and André Brasil raised some questions about good practices for Crossref DOI registration, asking for input from the scholarly communication community. In this post, Ludo and André reflect on the input received and discuss the approach to DOI registration that the MetaROR publish-review-curate platform is going to take.
As Crossref celebrated its 25th anniversary last year, we are highlighting some of the most active and engaged regions in our global community.
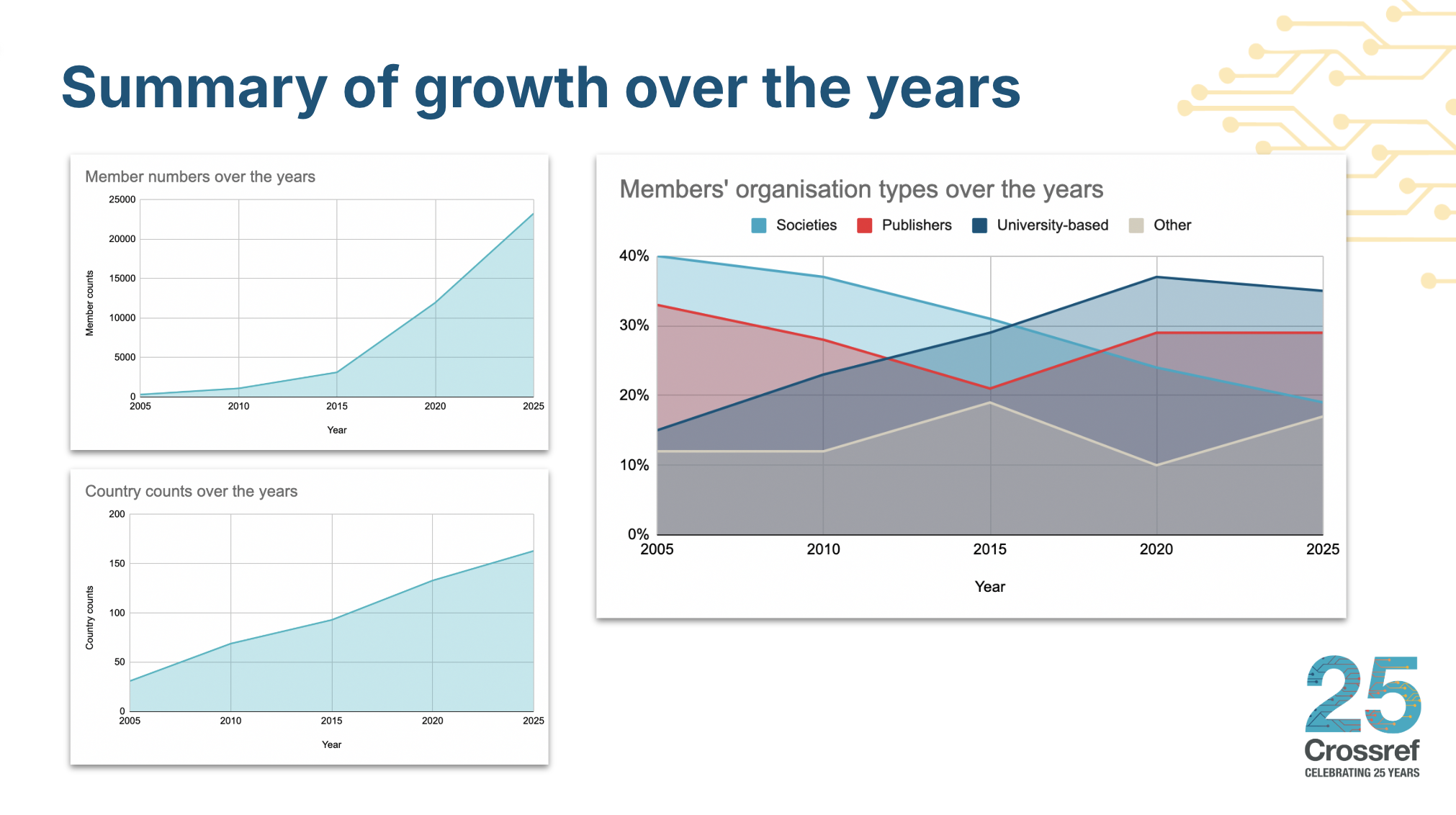
Over the past 25 years, the makeup of Crossref membership has evolved significantly; founded by a handful of large publishers, we now have more than 24,000 members representing 165 countries. Nearly two-thirds of them self-identify as universities, libraries, government agencies, foundations, scholar publishers, and research institutions.
It’s been said that Americans are unusual in tending to ask “Where do you work?” as an initial question upon introduction to a new acquaintance, indicating a perhaps unhealthy preoccupation with work as identity. But in the context of published research, “What is this author’s affiliation?” is a question of global importance that goes beyond just wanting to know the name – and perhaps prestige level – of the place a researcher works.
As Crossref membership continues to grow, finding ways to help organisations participate is an important part of our mission. Although Crossref membership is open to all organisations that produce scholarly and professional materials, cost and technical challenges can be barriers to joining for many.
Crossref turned twenty-five this year, and our 2025 Annual Meeting became more than a celebration—it was a shared moment to reflect on how far open scholarly infrastructure has come and where we, as a community, are heading next.
Over two days in October, hundreds of participants joined online and in local satellite meetings in Madrid, Nairobi, Medan, Bogotá, Washington D.C., and London––a reminder that our community spans the globe. The meetings offered updates, community highlights, and a look at what’s ahead for our shared metadata network––including plans to connect funders, platforms, and AI tools across the global research ecosystem.
Ed Pentz opened with thanks and perspective. He reflected on how it all began: twelve members, one shared goal — to make research easier to find and verify. 25 years later, the same goal underpins 174 million open metadata records, 1.9 billion citation links, and roughly 1.3 billion DOI resolutions each month. What started as reference linking is now a global network of relationships among people, institutions, and research outputs. Ed also reaffirmed the Principles of Open Scholarly Infrastructure (POSI) as the foundation of our operations and our collaborations with other community-governed infrastructures.
“Each number represents shared effort, trust, and long-term commitment,” Ed reminded us. “Open infrastructure works because people keep showing up.”
Crossref’s purpose as per the Certificate of Incorporation.
Following up Ed’s talk, we showed a video timeline, ‘25 years of Crossref’, tracing milestones from the first DOIs to today’s connected Research Nexus.
We featured perspectives from organizations that have built key scholarly infrastructure alongside Crossref over the years. A shared message ran through their talks: open infrastructure only works when it’s interoperable, community-led, and practical for the people who use it.
Urooj Nizami (PKP) described PKP and Crossref as “independent and interdependent,” using the archipelago metaphor to show how open software and shared metadata services connect local publishing to a global network.
Todd Carpenter (NISO) emphasized standards being a social, and technical contract, noting how persistent identifiers and reliable metadata underpin a broader knowledge graph—and why provenance and linking matter even more as AI systems remix content.
Abel Packer (SciELO) highlighted Latin America’s strong DOI coverage while pointing out where multilingual versions and preprint–article–data links still break visibility—arguing for metadata that connects versions, not splits them. [data point]
Soichi Kubota (J-STAGE/JST) showed how Crossref services (from citation linking, Cited-by, metadata, to Similarity Check) anchor Japan’s national platform and how deeper cooperation (e.g., Crossmark) will support richer, more reliable metadata.
Leena Shah (DOAJ) outlined DOAJ’s open index, renewed POSI commitment, and hands-on collaboration with Crossref—from the MoU and PLACE to help-desk coordination, gap analyses, and plans to boost DOAJ records via Crossref’s API and open references.
Susan Murray (AJOL) spoke of capacity building: with 900+ journals across 40 countries, benefiting from AJOL’s support in registering identifiers and metadata , and of their long-standing partnership with Crossref making it possible for journals with limited resources to take part.
These voices echoed a common call: Build bridges, not silos.
Governance and election results
Leading off the formal annual meeting, Lisa Schiff, Chair of the Crossref Board, looked back on our 25th anniversary as one marked by progress and problem-solving. She talked about moving all our systems to the cloud—a big step that makes the organization’s work faster and more reliable. She also spoke about ongoing efforts to maintain the research record’s trustworthiness, including adding Retraction Watch data and updating member terms. Lisa noted new ways we are making membership more accessible, like the lower $200 tier and the expansion of the GEM program.
Lucy Ofiesh brought it back to the role of the members themselves, reminding everyone that success still rests with its members. The annual meeting is when members directly influence Crossref’s direction––when each vote helps shape how we move forward together.
We extend our thanks to the Board members whose terms have concluded, and we congratulate the newly elected members who will carry the work forward.
Five directors were elected: Rebecca Wambua (Distance, Open and e-Learning Practitioners’ Association of Kenya), Damian Bird (CABI), Rose L’Huillier (Elsevier), Anjalie Nawaratne (Springer Nature), and Nick Lindsay (MIT Press).
We also thank the 2025 Nominating Committee for their thoughtful work guiding this year’s process and slate selection.
The Board plays an important role in making sure our governance remains community-led, transparent, and accountable. The volunteer members bring experience from research funders, publishers, and libraries, giving a balance of perspectives that help steer our long-term strategy and sustainability.
Tools in practice
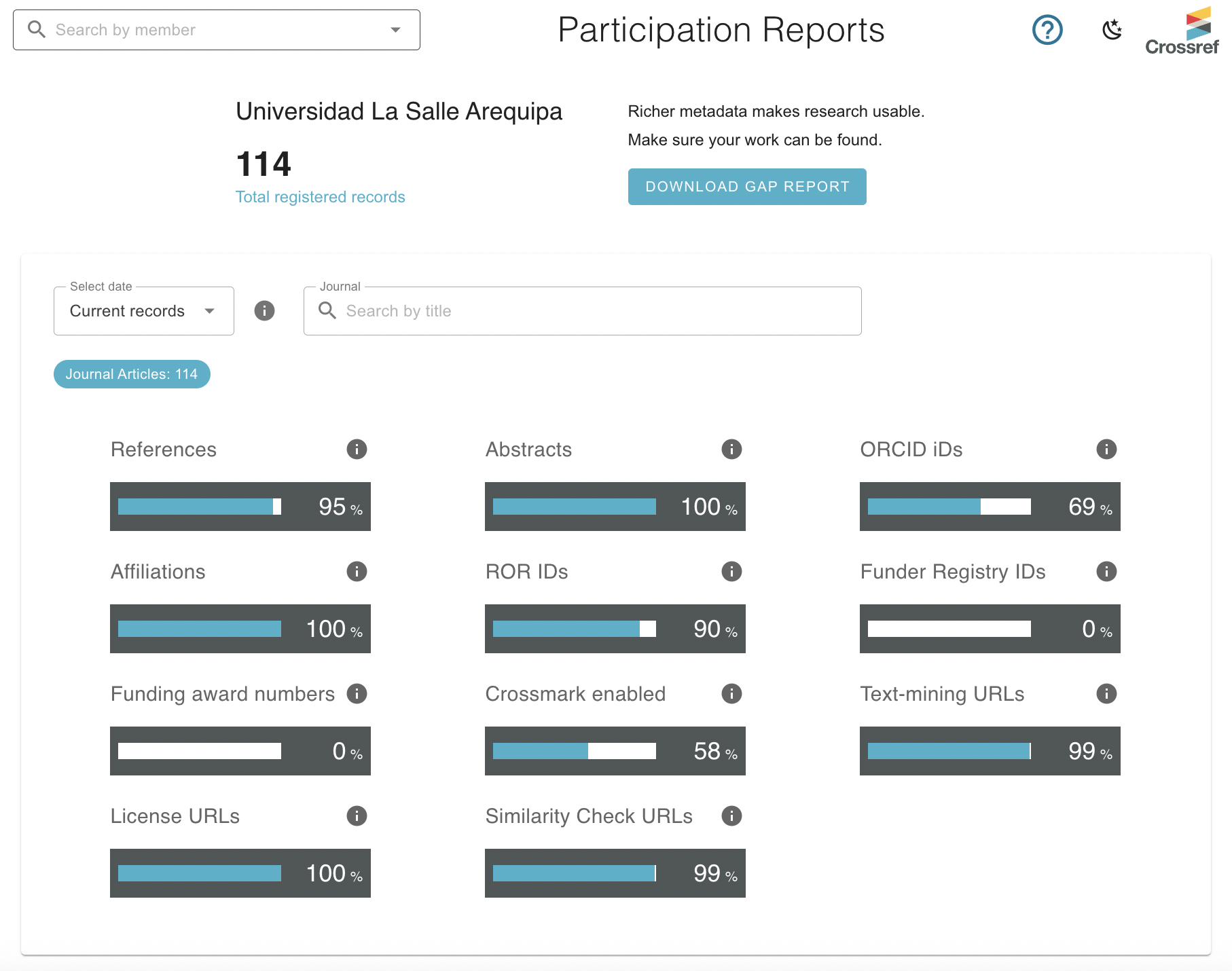
Then our attention turned to the tools that many members use every day. Patrick Vale walked participants through updates to Participation Reports and the Record Registration Form— designed to make working with metadata simpler.
Updated Participation Report for Universidad La Salle Arequipa (Peru), showing metadata element coverage percentages.
Participation Reports, first launched in 2018, have now been completely rebuilt as version 1.2. The refreshed interface runs on a new technology stack and supports morecontent types, and offers a new “download gap report” feature that generates a CSV list of records missing key fields—so members can identify and fix gaps directly.
Patrick then demonstrated improvements to the Record Registration Form, now streamlined for creating as well as editing records. The form includes real-time validation, auto-fill options for journals previously used, and the ability to edit existing records directly. Members can now easily add abstracts, funding data, licenses, and affiliations linked to ORCID and ROR—all within one place.
In the final demonstration, Luis Montilla, shared a “short research story”. He showed how anyone can explore Crossref metadata to uncover global participation patterns—turning what might seem like a mass of disconnected records into something meaningful once you start asking questions. He also shared a workflow that automatically retrieves and enriches data with country and regional information, then visualises member contributions and metadata coverage.
Luis also demonstrated an interactive notebook that lets users explore participation trends through radar charts and other visuals—illustrating how open data can help the community understand and improve the completeness of the scholarly record.
Crossref then & now
Amanda Bartell walked through how the community has changed over 25 years.
The membership has broadened dramatically: universities and scholar-led groups now form the largest share, and more organizations in Asia and Latin America have joined (with big growth in Indonesia and Brazil). Most members are small: 98% qualify for the lowest fee tier, and 57% participate via a Sponsor. In support of including members from smaller economies, Crossref launched a GEM programme, which will be expanding to 19 new countries in 2026.
With our growing membership, the needs of the community are evolving too, including expectations about Crossref’s role in preserving the integrity of the scholarly record.
“Our role in preserving the integrity of the scholarly record is focused on enriching the metadata to provide fuller and better trust signals while keeping barriers to participation low.” —Amanda Bartell, Crossref
In response to the growing membership across the globe, we launched our Ambassadors program in 2018. Johanssen Obanda highlighted the activities of what is now 50 volunteers across 38 countries. Ambassadors act as local contacts—running training sessions, organizing events, translating materials, and providing feedback from their regions. Over the past year, they’ve led 41 activities reaching around 1,200 people. Many also contribute to GEM outreach, metadata health checks, and regional events—often in local languages.
Roadmap highlights
Helena Cousijn outlined progress across three programs—Co-creation and Community Trends, Contributing to the Research Nexus, and Open and Sustainable Operations.
Along with already showcased progress with Participation Reports and the new Record Registration Form, the Community Trends program involves working in partnership with others on DSpace integration and OJS plug-ins consolidation. In the near future there’s also a consideration for piloting AI detection tools.
The Contributing to Research Nexus program carried out a consultation with Metadata Plus subscribers, and develops a new data citations endpoint for the Crossref REST API. This team is also developing further matching services, in the first instance looking to match funder metadata to ROR IDs.
Finally, Helena discussed the recent accomplishment of the Open and Sustainable Operations program, the migration of our database from the data centre to the cloud with Amazon Web Services. Other projects in this program involve ravamping resolution reports, rebuilding the Crossref authentication system, and launching new metadata schema.
Resourcing Crossref for Future Sustainability (RCFS)
RCFS program is focused on equity, simplicity, and revenue balance. Kora shared recent developments and next steps:
:
A new $200 membership tier (for organizations with ≤$1,000 in publishing revenue/expenses) takes effect on January 1, 2026; more than 3,000 members have already moved into it.
We will keep “publishing revenue/expenses” as the sizing basis for publishers while funder sizing is still under review.
Volume discounts for content registration end on January 1, 2026.
Backfile discounts for theses/dissertations and conference proceedings are under review.
Peer-review fees are normalized at $0.25 for the first review of a work, with subsequent reviews (same member, same work) for free
Behind the scenes: metadata, data science
Patricia Feeney reviewed recent and upcoming changes to our metadata schemas. Earlier this year, we began accepting ROR IDs as funder identifiers and released schema 5.4, which added versioning across all record types, a new status field for preprints, and a way to label citation types (like data sets, software, or blog posts).
Coming soon, Crossref will add grant DOIs to funding metadata and release schema 5.5, which supports the CRediT contributor vocabulary and allows multiple contributor roles. A new grant schema will follow, including support for beneficiaries, project identifiers (like RAiD), and repeatable roles. Looking ahead to 2026, our plans to overhaul how names and organizations are modeled, add richer funding and data-availability statements, and expand abstract and multilingual metadata support. A new Metadata Advisory Group has also been formed to guide work on multilingual fields, subjects, keywords, and relationship modeling.
Finally, Patricia announced plans to deprecate older schemas—a gradual, multi-year process—to simplify and modernize our metadata structure. She highlighted the importance of stronger relationships, richer records, and practical improvements that make metadata more useful across the community. That focus on connection carried directly into the next session about building through data science.
Data science at Crossref
Dominika Tkaczyk introduced the new data science team, formed a few months ago as part of the technology group. The team was created because of the growing scale and complexity of the data Crossref manages, driven by the expanding scholarly community. Their role is to use data science to assess, improve, and enrich scholarly metadata.
Their work falls into two areas: data analysis and insights—to help Crossref understand the scholarly record and guide decisions—and data services and workflows—to apply data science in building and maintaining production systems. Examples include studying overlap between scholarly databases and improving metadata quality. The session then focused on two projects: creating an internal data processing environment and developing metadata matching services.
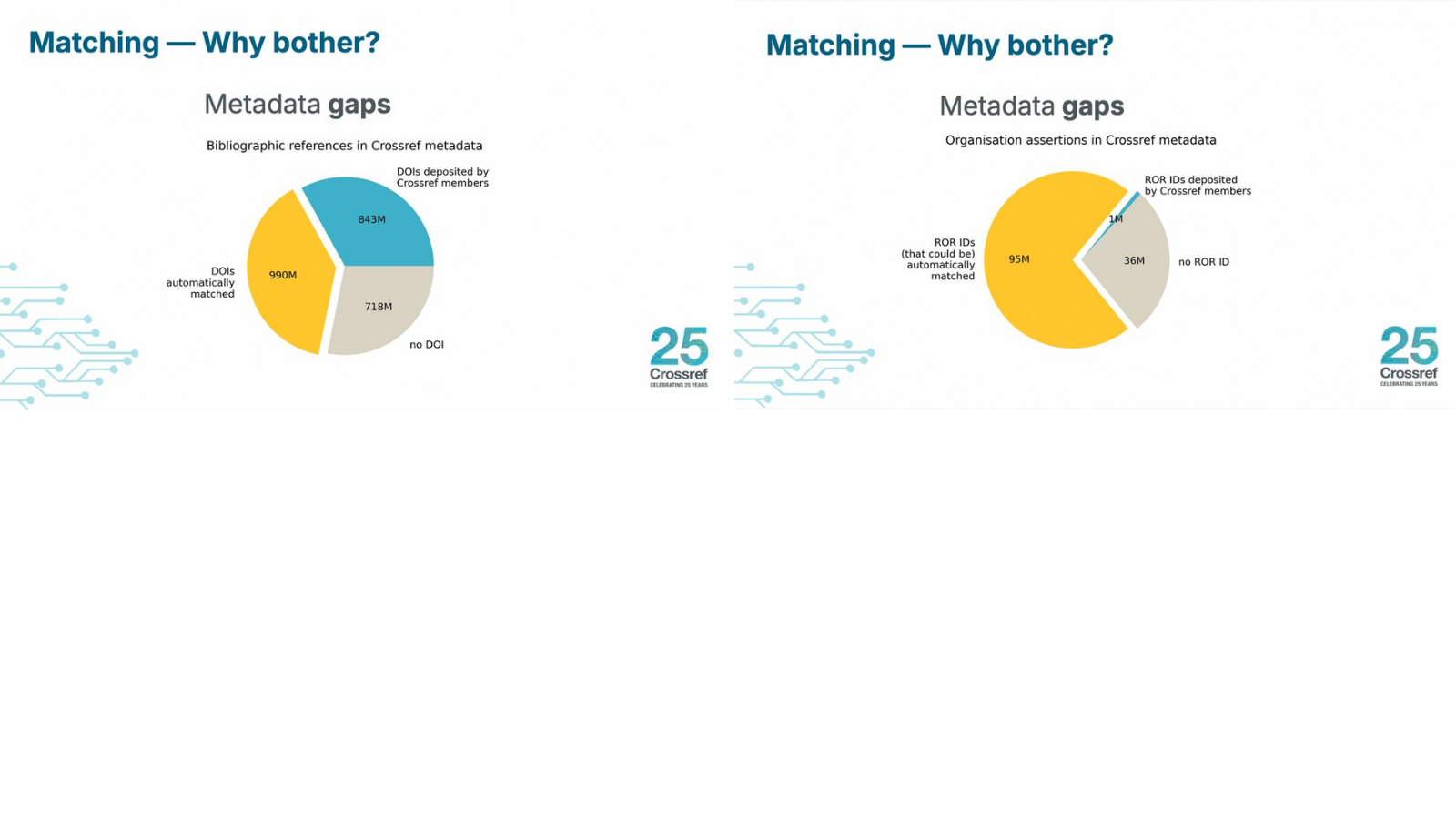
Alex Bédard-Vallée described the team’s first project: building a data lake to bring together fragmented data from different systems. Previously, data were split across silos like the REST API, internal logs, and production databases. It enables tracking of reference deposits, closing 718M citation gaps. The system already enables analyses that were previously impractical, such as tracking how many members include reference metadata in deposits. It will also power new dashboards, monitoring tools, and other data-driven initiatives that support the integrity of the scholarly record.
Jason Portenoy then outlined the metadata matching project, which links pieces of information (like citations, funder names, or affiliations) to their identifiers such as DOIs or ROR IDs. He gave examples including reference-to-DOI, funder-to-ROR ID, affiliation-to-ROR ID, grant-to-DOI, and preprint-to-published-article matching.
He explained that much metadata is already deposited by members but large gaps remain. For example, among more than a billion citation links, about 843 million already include DOIs, while another 718 million references can’t yet be matched. The goal is to close these gaps to build a more complete and connected scholarly record—the “research nexus.”
Community highlights
Martyn Rittman, Program Lead, and Kora each opened the community highlights over the two days by noting that everyone presenting is sharing how they use metadata and contribute to the broader ecosystem.
Crossref does not exist without our members and the broader community—people who provide metadata and people who use the metadata. That’s why we’re here.” ~ Martyn Rittman
Antoine Drouin (Fonds de Recherche du Québec) shared that FRQ joined Crossref earlier this year and created 22,000+ grant and scholarship DOIs, linking grants to outputs and improving interoperability with ORCID, ROR, and Crossref grant IDs.
Agon Memeti (University of Tetova) shared findings of his analysis of abstract metadata coverage across 2024 articles from 13 university journals.
Charlie Rapple (Kudos) presented a Crossref-supported study on how researchers engage with the UN SDGs and described Kudos’ work explaining research for wider audiences. A survey of ~4,500 researchers showed strong awareness, regional differences in SDG priorities, and some targeted budgets for promotion, alongside challenges in publishing SDG-focused local research in prestige venues.
Pia Kretschmar (SCOAP3) outlined integrating Crossref metadata into new SCOAP³ open science elements in Phase 4; SCOAP³ funds OA publishing in high-energy physics and has covered 78,000+ articles. Publishers are scored on elements such as metadata provision to Crossref, identifiers, and links to datasets/software; completeness was checked via the Crossref API, results varied, and evaluation continues next year.
Barbara Rivera (Barcelona Declaration) introduced the Declaration, its four commitments, and its community of 125 signatories and 52 supporters, including Crossref. Working groups are executing a joint roadmap, with recent actions such as a funding-metadata roundtable and upcoming surveys on metadata frameworks and repository workflows.
Hans de Jonge (Dutch Research Council, NWO) presented his and Bianca Kramer’s recent study (as of 10/23/25 Preprint, not yet reviewed) of metadata completeness in Crossref among publishers using different manuscript submission systems. They compared six metadata types across major publishers and found that differences had more to do with workflow choices, customization, and policy than with the system itself.
Nurul Ain Mohd Noor (UMT Press, Malaysia) described UMT Press’s evolution since 2003, rebranding in 2007 and joining Crossref in 2020. Nurul explained how registering their metadata with Crossref increased citation visibility and indexing across databases.
Achal Agrawal (PostPub) introduced PostPub’s dashboard providing retraction statistics by country and institution, supported by a Catalyst Grant from Digital Science, and shared their journey through disambiguation challenges.
We closed the meeting with a panel discussion on the Research Nexus in the real world: What is the impact and potential of open scholarly metadata. Ginny Hendricks, Crossref; Dominika Tkaczyk, Crossref; Bianca Kramer, Barcelona Declaration on Open Research Information; David Oliva Uribe, UNESCO; Amber Osman, XploreOpen; Mariángela Nápoli, CONICET-IICE UBA-FFYL; Crossref; Kazuhiro Hayashi, National Institute of Science and Technology Policy; Science Council of Japan, shared a diversity of perspectives, which we’ll share in an upcoming blog.
You will find outputs from #Crossref2025 on our website, which you can cite as `#Crossref2025 Annual Meeting and Board Election, 22-23 October 2025 retrieved [date], https://doi.org/10.13003/431937misogo ‘.