A couple of months ago, Ludo Waltman and André Brasil raised some questions about good practices for Crossref DOI registration, asking for input from the scholarly communication community. In this post, Ludo and André reflect on the input received and discuss the approach to DOI registration that the MetaROR publish-review-curate platform is going to take.
As Crossref celebrated its 25th anniversary last year, we are highlighting some of the most active and engaged regions in our global community.
Over the past 25 years, the makeup of Crossref membership has evolved significantly; founded by a handful of large publishers, we now have more than 24,000 members representing 165 countries. Nearly two-thirds of them self-identify as universities, libraries, government agencies, foundations, scholar publishers, and research institutions.
It’s been said that Americans are unusual in tending to ask “Where do you work?” as an initial question upon introduction to a new acquaintance, indicating a perhaps unhealthy preoccupation with work as identity. But in the context of published research, “What is this author’s affiliation?” is a question of global importance that goes beyond just wanting to know the name – and perhaps prestige level – of the place a researcher works.
As Crossref membership continues to grow, finding ways to help organisations participate is an important part of our mission. Although Crossref membership is open to all organisations that produce scholarly and professional materials, cost and technical challenges can be barriers to joining for many.
Having joined the Crossref team merely a week previously, the mid-year community update on June 14th was a fantastic opportunity to learn about the Research Nexus vision. We explored its building blocks and practical implementation steps within our reach, and within our imagination of the future.
Read on (or watch the recording) for a whistlestop tour of everything – from what on Earth is Research Nexus, through to how it’s taking shape at Crossref, to how you are involved, and finally – to what concerns the community surrounding the vision and how we’re going to address that.
Summary of presentations
Click on image above to access the presentation.
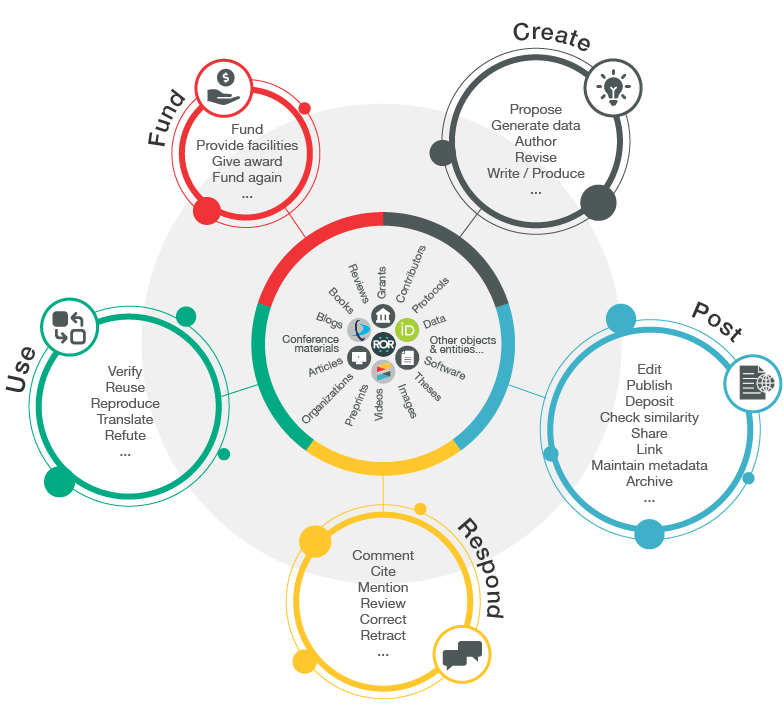
The idea is simple in principle: scholarly records ought to be transparent – available to examine and learn from for all. Much of scientific production and communication these days has a heavy digital footprint so the Nexus is nothing but simply connecting the loose strands, right? Yet, as the scholarly record is a reflection of the continuous progress made by multiple actors within the context of scientific structures and processes, bringing the Nexus to life is a little short of simple.
“What we think of as metadata is expanding, and the notion of ‘record types’ is changing” – said Ginny Hendricks. A great majority of scholarly ‘objects’, whether they are data sets, research articles, monographs, or others, undergo many processes (including review, publication, licensing, correction, derivation) and influence knowledge and practice over time.
Making that progress visible and discoverable will allow for tracing the development of ideas and changes in our thinking over time. Transparency of the complete scholarly records will help to understand the impact of science funding and changing policies. It can support a more robust and comprehensive assessment of research, and contribute to improving integrity within as well as public trust in sciences.
Patricia Feeney has given us reasons for optimism in building a robust Nexus. She’s shown areas of greatest growth in metadata reported to Crossref and shared a public roadmap of types of information we’re asked to enable in the future. We’re seeing a true boom of datasets and peer review reports registrations, and the relationship metadata for our records is improving too. At the dawn of defaulting to open references, 44% of records we hold have associated references and that is growing. Provision of the newly enabled affiliation information (ROR IDs) is on the rise, as is the funder information. Some conversations and questions followed highlighting the need for further guidance in these areas.
To make a case for enriching metadata records, Martyn Rittman demonstrated examples of traceability of research influence on realities outside academia. He captured recent examples of data citations and other references present not just between scholarly papers, but also in policy documents and popular media. These allow for greater discoverability of literature – but also show the public influence and impact of the research and the work’s context in our wider society.
While Martyn shared our blue-skies aspiration to streamline Crossref’s APIs to offer insight to all these relationships with a single service, Joe Wass grounded those ambitions in the reality of technical work underway. His team’s attention is divided between three main areas. They continue to maintain and de-bug our existing infrastructure. They are developing self-service solutions for members. Finally, they are mapping and planning improved infrastructure, evaluating technology against the Research Nexus vision.
Bringing it back to the source (of metadata), Rachael Lammey offered a very practical guide to key activities enabling Research Nexus that all members can take on now. She highlighted the benefits of collecting and registering data citations, ROR IDs, and grant funding information. She went on to talk about challenges of subject classification (at a journal level) that our research and development efforts are focusing on at the moment.
Summary of discussions
Publishing has changed dramatically and our members recognise increasing opportunities for transparency of the scholarly record. Breaking the distant vision of Research Nexus down into actionable chunks made it more relatable for call participants. Many reflected on seeing their place in it properly for the first time. Yet, challenges remain and many were brought to the fore in the discussions.
The reliability and usability of the technology for registering metadata with Crossref needs to improve. We need to do better in supporting multi-language and multi-alphabet information. Not just developing systems anew, but also streamline the way content is registered and annotated, and continue to disambiguate the competing identifiers. Different record types, chiefly books, present specific challenges in this regard. Finally, making all that metadata accessible and usable is key to enabling insights from the rich data we collectively make available.
Technology is important, but won’t overcome the barriers that exist in the mindsets. Siloed thinking means that publishers may not be sensitive to benefits that improved relationship metadata could have for colleagues working on assessment, even within the same institutions. Greater guidance or best practices for new identifiers, such as ORCID, ROR, grants, would allow more publishers to get on board with the changes. Researchers often don’t help the cause either – many don’t realise the role and benefits of metadata for their work and are reluctant to provide rich information related to it, perceiving it as a bureaucratic burden.
In a nutshell, I learnt that – while the concept of Research Nexus is pretty complex – we’re all already participating in making it a reality. I’m grateful to the call participants for sharing their challenges and ideas so generously. It means we can work to address those. I’ll be sure to follow-up on requests for support and clearer guidelines about citing data, recording ROR IDs and grants information in the metadata, and we’ll engage our community on complex topics of record updates (corrections, retractions and versions). Be sure to keep in touch with the conversations on the Community Forum. I’ll see you there!